
Quantifying Linguistic Variation
5 Jul 2024
As aptly noted by my PhD siblings, we are now PhDone! Tak to all of you who made this journey possible and fun!
Let's go on a high-level, 10-minute speedrun of what you can find in the full PhD thesis, and gather the related papers and nifty resources. Also, don't miss out on our lab's tradition of over-produced video presentations! 📽️
Hopefully, there's something that can help you out in your own research!
I have been struck again and again by how important measurement is to improving the human condition.
—Measuring Progress (Bill Gates, 2013)
Coming Up
- What Is Linguistic Variation?
- An Approach to Quantifying Variation
- Typological Variation
- Domain Variation
- Task Variation
- What's Next?
What Is Linguistic Variation?
That's a tough one. I mean, "Hvad er sproglig variation?", eller, "Was ist sprachliche Variation?", oder, "Cos'è la variazione linguistica?", それとも, 「言語間の差異とは?」. You get the idea.
As anyone can attest to, it becomes more difficult to understand each other the farther you stray from home. Effectively, this is variation across different language typologies (i.e., language families and the like):
Despite the different languages in this example, they are all actually asking the same question. Of course, we can communicate about much more than that in any language—hence, we need to add another axis to how language can vary:

Venturing outside of a known domain is painfully obvious when we leave language class, just to find that 'this is a pen', doesn't really transfer to ordering a double-shot cortado on oat milk, thank you very much. I'm sure you can tell where this is going: Of course, there are even more axes across which language can vary (e.g., social context, familiarity, politeness levels such as in Japanese). Put together, we call these axes Variety Space.
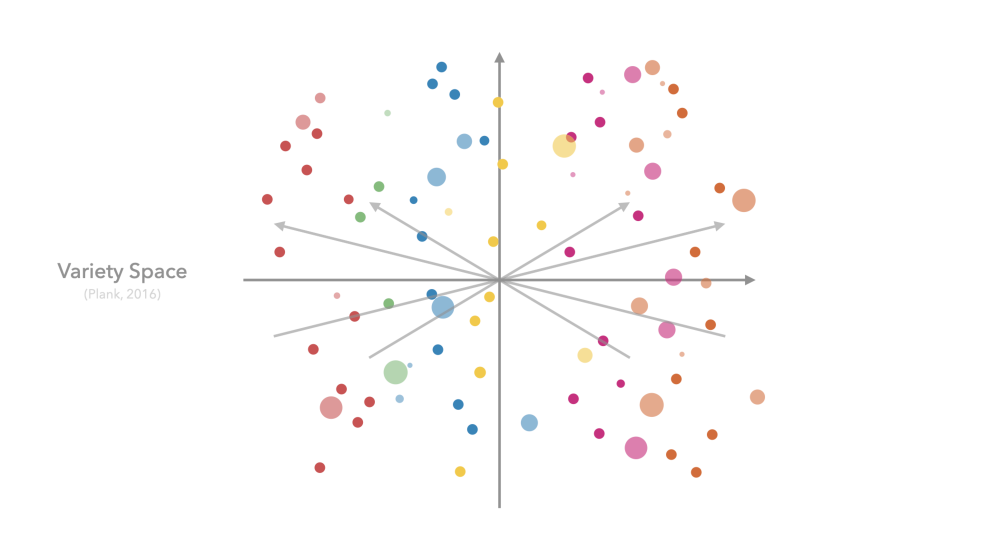
Intuitively, we navigate Variety Space every day, and this ability is extremely important, since every time we stray too far, we lose mutual intelligibility. This actually also applies to Language Models (LMs), in the sense that when trained on one language variety, they are less accurate on varieties that are further away. Training on all of Variety Space is impossible in practice given that we simply don't have data in all languages on all topics, in all social context, etc.
Measuring where we are in Variety Space can help us tackle this issue in a more deliberate way. Not only does it tell us how likely it is that one language variety will help with understanding another, but by combining multiple dimensions, we are able to select data with a combination of beneficial properties: E.g., if we don't have data in a particular language and domain, we could select data from a similar language (but different domain), and from the same domain (but a different language), in order to fill these gaps. How shall we do this?
An Approach to Quantifying Variation
Linguistics literature provides many useful axes across which language can vary, but it's difficult to combine and apply these definitions at scale. Luckily, LMs not only require, but thrive on scale. In essence, all contemporary LMs use gigatons of unlabeled data to approximate the distribution over all conceivable sentence completions:
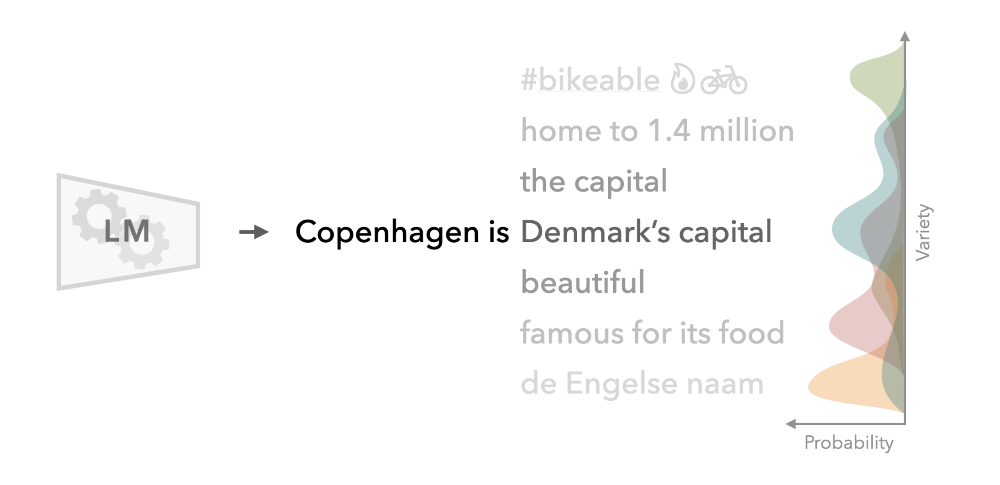
Diverging from this distribution is typically bad for LM performance, but for us, it's an indispensable tool for measuring the distance from one language input to another, i.e., for quantifying linguistic variation.
Using LMs to measure variation gives us a number, but it does not tell us what this number means. To interpret this metric, we need to link it back to the human-defined axes of linguistic variation. Here, we build on interpretability methods, which—as the name suggests—allow us to probe for subspaces in Variety Space, within which LM representational similarity has a specific interpretation.

In the thesis, we focus on the variety subspaces of typology and domain, as well as how these interact to form tasks in Natural Language Processing (NLP).
Typological Variation
What is a language? Well, here are three sentences, which are obviously written in different languages:
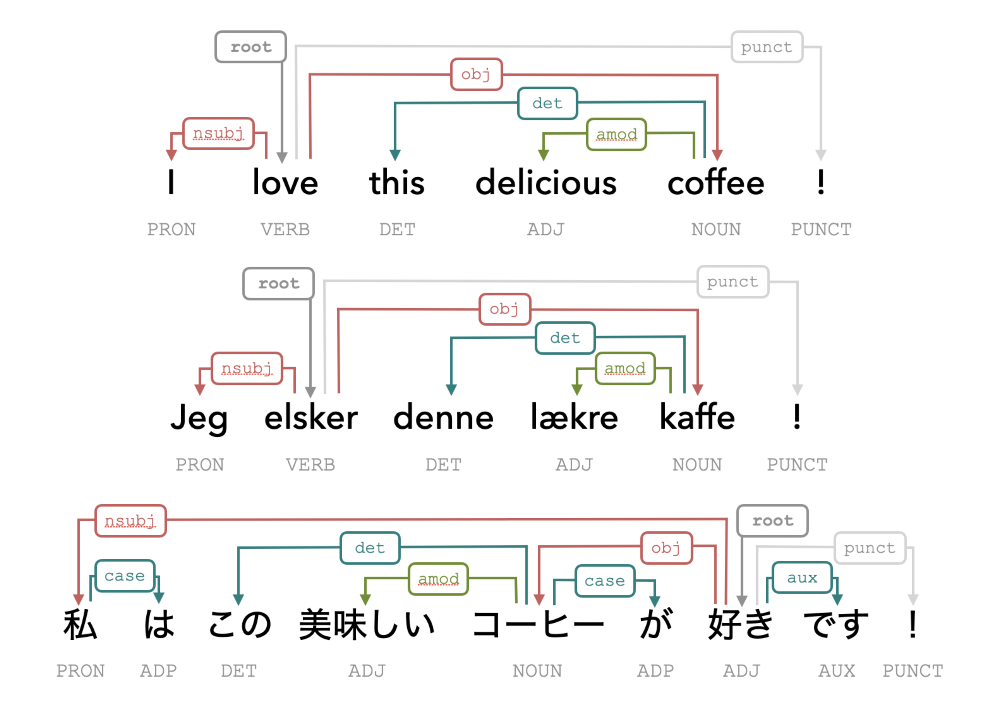
Note that they all mean the same thing, but are mostly mutually unintelligible. Why do we nonetheless understand each other when we 'speak the same language'? Although there is no golden rulebook, we typically follow certain rules consistently within a community. In the example above we highlight one of these rules: syntax.
Here, we follow the annotation guidelines from the Universal Dependencies project (UD), such that we can compare syntax across languages. This already shows us how English and Danish, while looking (and sounding) extremely dissimilar, actually follow exactly the same syntax in this example. Since these two belong to the same typological family, this makes a lot of sense. Meanwhile, Japanese (a typological isolate) is kind of doing its own thing, and doesn't even need a verb to express the same meaning. How do we measure this distance quantitatively?
Dependency Probing
In Müller-Eberstein et al. (2022a), we proposed the first method for extracting the full graph from each sentence above, also called a dependency tree. The method itself, as noted by Reviewer 2, "appears relatively straightforward", which I'll take as a compliment. Indeed, DepProbe only needs two small matrices to extract these trees + labels from the LM, allowing us to save about 3000x parameters compared to training the whole LM for this purpose.
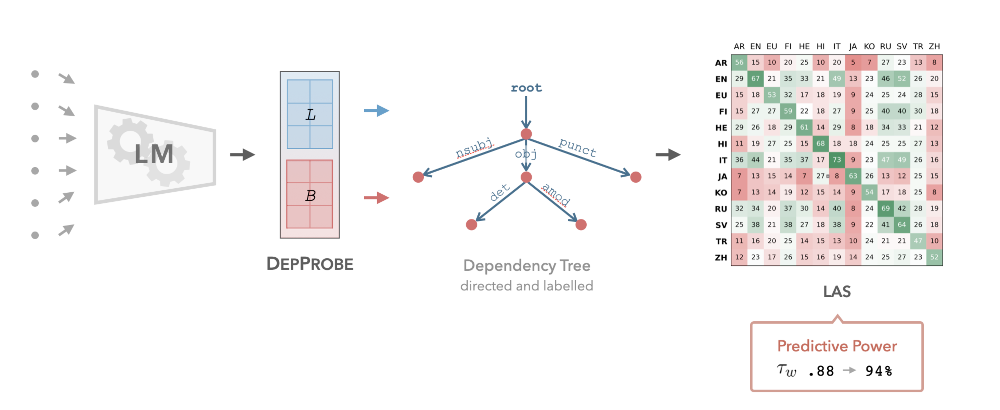
By comparing how well this Dependency Probe overlaps across languages, we can now very efficiently test how syntactically similar one language is to another. In our experiments across 169 language pairs, we show how DepProbe can be used to predict the best training language in a zero-shot transfer setting 94% of the time. In follow-up work with Samardžić and colleagues, we further show that this approach maintains a correlation of .66 with final performance even across 116 languages, i.e., 27.5k transfer combinations.
Sort by Structure
Beyond measuring which data we should use to train a model, we can also use DepProbe to predict which LM will parse syntax well for a given language. Essentially, the more accurately we can reconstruct dependency trees for a language based on an LM's representations, the better it should be suited for that language. We evaluate this for 9 languages and 22 different LMs, and find that DepProbe is able to choose the better model 79% of the time.
This feeds into the larger question of how NLP practitioners choose an LM for a given language and task. The state-of-the-art in this area is... following your intuition. Since this isn't particularly scientific, my PhD siblings and I followed-up on this general 'measure before you train'-approach by verifying whether evidence from subspace measures can predict which LM will perform best on a task prior to training. We evaluated 7 LMs on 10 tasks, and found that task subspaces predict the better model 71% of the time, and that we can outperform humans (ourselves and NLPeers) by a factor of 3—even in unituitive cases—showing that evidence > intuition.
Resources
For when you want to extract syntactic dependency trees from an LM:
🛠️ DepProbe Implementation (extract some trees from your favorite LM).
📄 Probing for Labeled Dependency Trees (Müller-Eberstein, van der Goot and Plank, 2022a).
- 📽️ DepProbe Presentation (watch us struggle with matrix multiplication).
- 📄 On Language Spaces, Scales and Cross-Lingual Transfer of UD Parsers (Samardžic et al., 2022). Follow-up with 116 languages.
For when you want to rank which model encodes the syntax of your language best:
📄 Sort by Structure: Language Model Ranking as Dependency Probing (Müller-Eberstein, van der Goot and Plank, 2022b).
- 📽️ Sort by Structure Presentation (RIP Mike).
- 📄 Evidence > Intuition: Transferability Estimation for Encoder Selection (Bassignana*, Müller-Eberstein*, Zhang* and Plank, 2022). Follow-up predicting LM performance on 9 more tasks.
- 🛠️ LogME for LMs Implementation (estimates the fit of an LM for your task).
Domain Variation
What is a domain? Compared to variation across linguistic typology, this question requires more intuition to answer. Let's check out these examples:

While not direct translations, these encyclopedia and travel guide entries all cover the topic of 'Copenhagen'. By highlighting concepts that match across languages in the same color, we can see how the city takes on different surface forms (e.g., Copenhagen, København, コペンハーゲン), and co-occurs with different context words depending on the genre (e.g., population numbers versus touristic experiences).
In addition, I've also underlined all adjectives in these paragraphs. Even though these excerpts are short, notice that there are 4 adjectives in the encyclopedia entries and 8 in the travel guides. This is a pretty large difference, considering that these genres are intuitively very similar (i.e., both communicate factual information), and despite the fact that travel guides in different languages highlight different aspects of the destination. This is a first indication of how the typological property of syntax may be interacting with the domain property of genre across languages. But first...
Can Humans Identify Domains?
This was a particularly fun question to tackle with colleagues at NLPnorth. In this study, we asked 12 annotators to annotate 9.1k sentences from the English GUM corpus with respect to topic and genre. While genre was defined by the source of each data point listed in the original dataset, topic lacked a gold truth label and was instead chosen based on the three-layer Dewey decimal classification system for libraries. The final dataset, which we named TGeGUM (Topic-Genre GUM; coincidentally, 'tyggegum' is 'chewing gum' in Danish), contains 32.7k multi-annotations for topic and genre. Because these are such fuzzy concepts, we can very nicely see this uncertainty reflected in the human annotations:
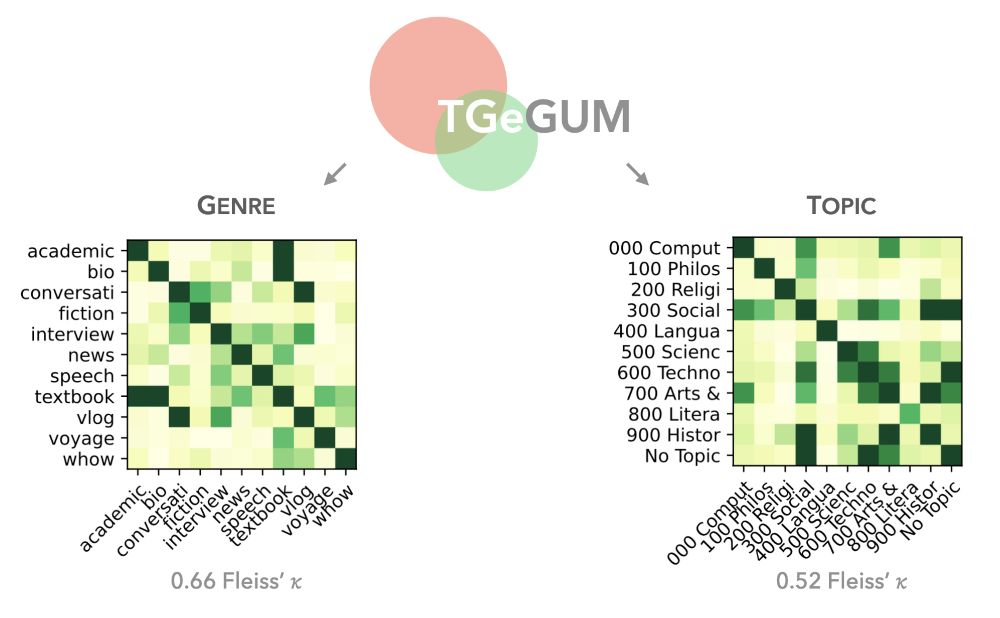
Considering that we did not optimize for agreement across annotators, we get a decent 0.66 Fleiss’ 𝜅 for genre and a 0.52 Fleiss’ 𝜅 for topic. Nonetheless, we see that intuitively similar genres (e.g., vlogs and converstations), as well as topics (e.g., social sciences and history) are often mixed up. This shows us how both of these variety dimensions are really difficult to pin down, and that a continuous spectrum might be better suited to quantify them.
Genre across Languages
The previous study focused on English, but what about genre across languages? This is extremely difficult to answer, since (a) most datasets with genre labels are only available in English; (b) aligning genre labels across languages is non-trivial due to different definitions across datasets etc. Luckily for us, the Universal Dependencies project not just annotates syntax, but also has a metadata field for genres. Not only that, it also spans 161 languages (as of May, 2024)—making it one of the most diverse cross-genre, cross-lingual annotated resources to date.
Unfortunately for us, genres are only annotated at the treebank level, i.e., each decentralized contributor to this open source project jots down which genres are in their sub-dataset, but does not necessarily tell us which sentence belongs to which genre.
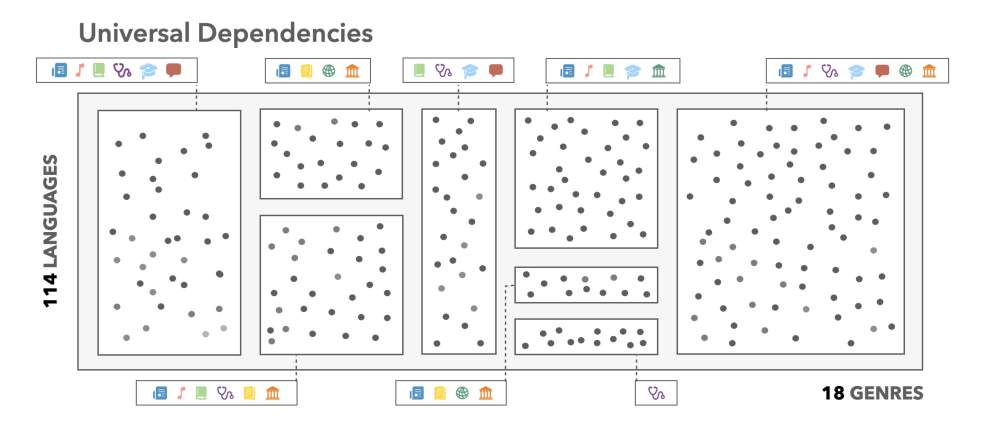
I don't know about you, but neither do I speak 114 languages, nor does my three-year PhD allow me to go through 1.5 million sentences manually. Using LMs to measure genre similarity also doesn't work out-of-the-box, since other variety dimensions, such as language typology, far outweigh these subtler differences. Again, we need to link the quantitative, but uninterpretable LM representations, to qualitative, but interpretable linguistic properties. To achieve this for genre, we turned to weak supervision from the treebank-level genre metadata, and apply a bottom-up bootstrapping strategy to cluster data with similar genre characteristics closer together. The difference before and after this genre amplification is quite striking:
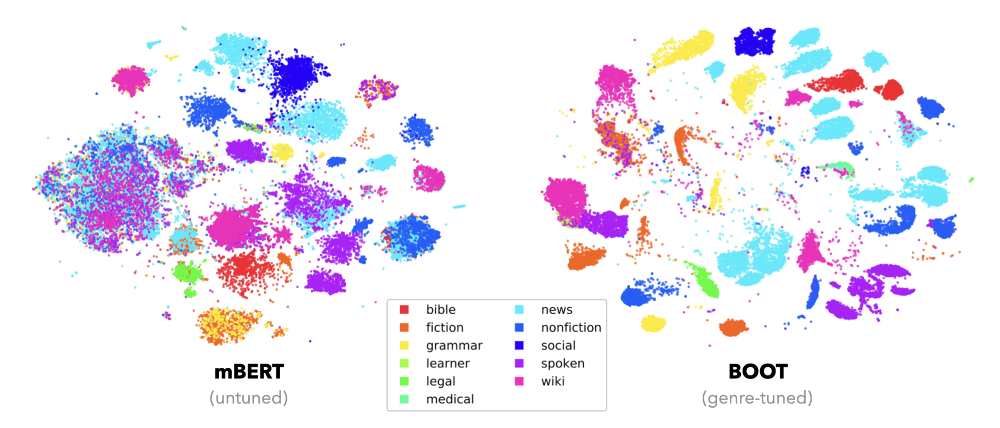
While different genres are mostly clumped together in the out-of-the-box LM, after our bootstrapping procedure, there is a much clearer separation. This allows us to quantify the genre distribution across 114 languages for the first time:

Having access to this distribution is extremely useful when we're working with under-resourced languages. We demonstrate this by training syntactic dependency parsers for 12 heavily under-resourced languages in UD. Take Chukchi, for instance, a language spoken by around 8.5k people in north-eastern Siberia. There is no training data for Chukchi in UD, meaning that we need to train on some other data and then apply it zero-shot to this target. Our experiments show that selecting training data from other languages, which we identify as being in the same genre (e.g., spoken), leads to the highest performance, while requiring 8x less data than training on everything available. While this is great, and we got to stamp our paper with 'state-of-the-art' for many of these languages, overall performance is still extremely low, meaning that we're unfortunately still quite far off from ChukChiPT.
Resources
For when you want to study how humans perceive genre and topic:
📄 Can Humans Identify Domains? (Barrett*, Müller-Eberstein*, Bassignana*, Brogaard Pauli*, Zhang* and van der Goot*, 2024).
- 📚 TGeGUM Dataset.
- 📽️ TGeGUM Presentation (in which we eavesdrop on our students' conversations... for science).
For when you want to analyze genre across languages:
📄 How Universal is Genre in Universal Dependencies? (Müller-Eberstein, van der Goot and Plank, 2021b).
📄 Genre as Weak Supervision for Cross-lingual Dependency Parsing (Müller-Eberstein, van der Goot and Plank, 2021a).
- 🛠️ Implementation of Genre Amplification Methods.
- 📽️ Cross-lingual Genre Presentation (get a guided tour of the genres of Copenhagen).
- 📄 Relation between Cross-Genre and Cross-Topic Transfer in Dependency Parsing (Danilova and Stymne, 2024). Excellent follow-up work, showing in more detail how genre is distributed across languages in UD, and what automatic methods like ours retrieve.
Task Variation
What is a task? In most Machine Learning fields this seems like a trivial question: It's mapping an input x to its corresponding output y. For most of my time in NLP, the prevailing paradigm of what a task is has somewhat resembled the following:
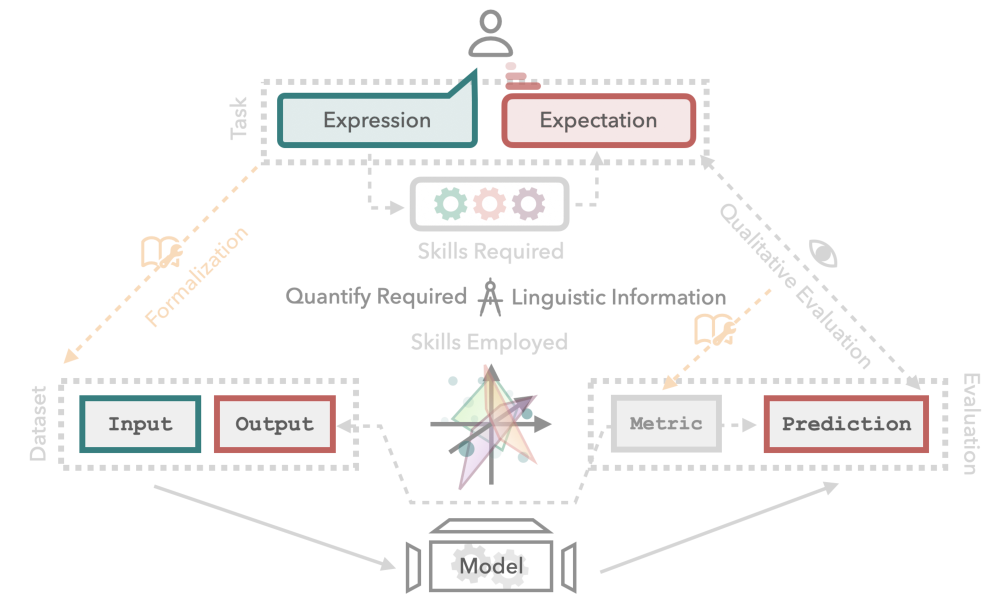
Generally speaking, an NLP task is to process a natural language expression to fulfill some expectation (e.g., given this sentence, classify its sentiment). In order to automate this process, we first formalize them into machine-readable inputs (e.g., UTF-8-encoded text) and outputs (e.g., numeric label). On this dataset, we can then train a model to produce machine-readable predictions. To evaluate the quality of our model, we can either manually go over the predictions to check if they match our expectations (i.e., qualitative evaluation), or formalize this process in an automatic evaluation metric.
In Litschko et al. (2023), we argue that this cycle builds user trust, as we can quantify how likely a given model will do well on similar tasks in the future. With the advent of larger, instruction-tuned LMs, this traditional cycle breaks down, as tasks become more complex and expectations become harder to formalize in automatic metrics. For instance, whether a model has successfully completed the task, "write a polite German email to my main PhD advisor, asking for time off tomorrow", depends solely on the user's subjective interpretation. What would you need to know before you would trust the model to send this email off automatically?
Subspace Chronicles
Even if composing just the right email is a complex task, it requires the model to represent certain types of linguistic information well. E.g., it needs to have a good grasp of German syntax, follow the genre conventions of email, needs to hit the right level of politeness, etc. Effectively, it needs to encode well-formed subspaces for each of these properties, which can interact to form the total information required to write that email.
These task subspaces are closely linked to the variety dimensions we identified for syntax and genre, in that both are spaces within which a specific type of linguistic information is particularly salient. To understand how this task-specific information gets into LMs in the first place, we collected the Subspace Chronicles:
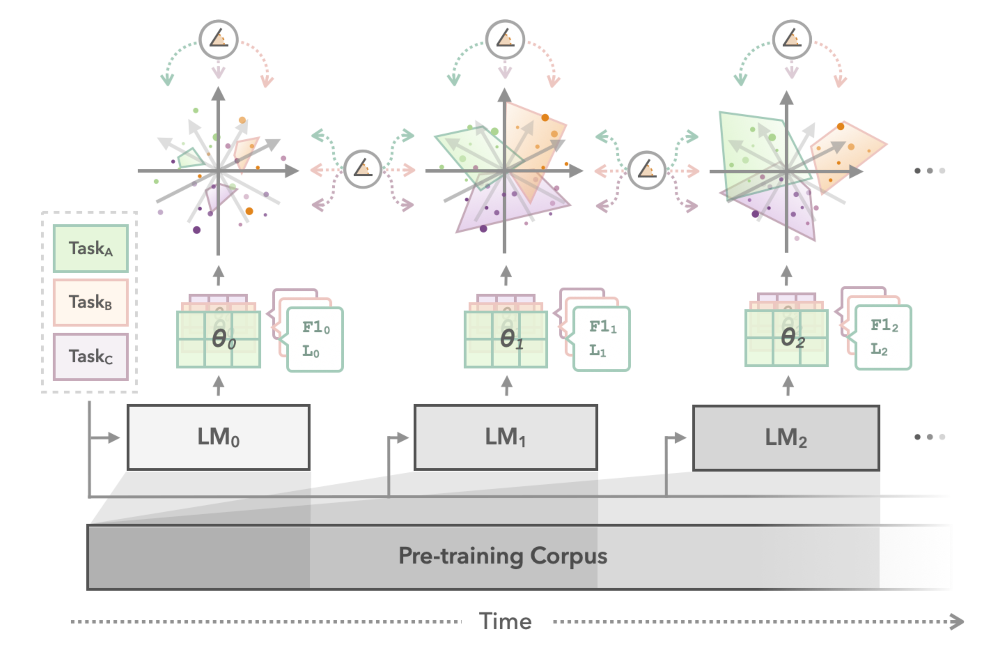
Instead of looking into how linguistic information is represented after an LM is fully trained, we take intermediate snapshots and check how the information changes across training time. By looking not just at the performance on specific tasks, but also at how the information is encoded, we can identify some important dynamics regarding how LMs learn:
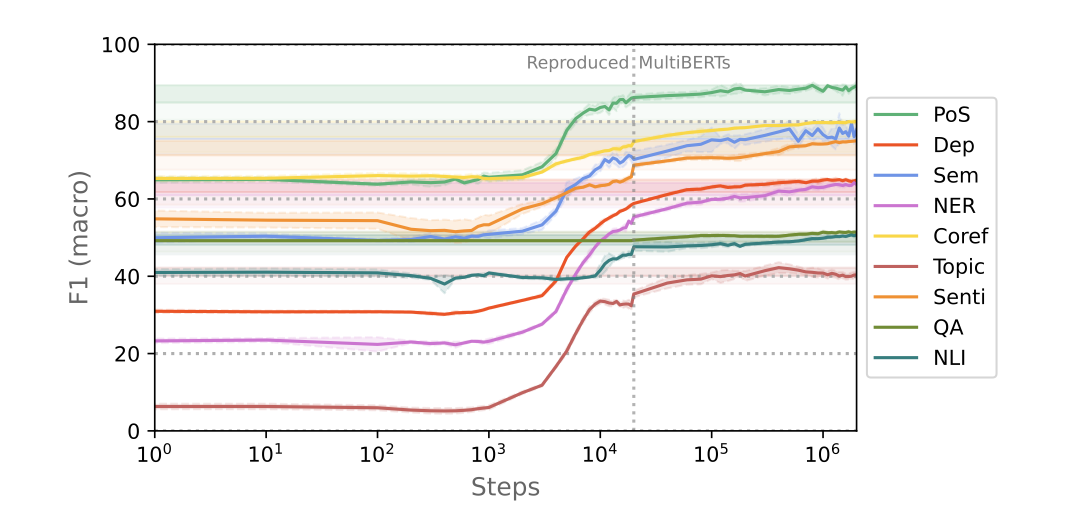
For one, we see that, in terms of performance, most learning happens around 10k steps. This means that even for languages with fewer data, we may be able to get decent LMs with just 0.5% of full training. Let's take a closer look of what is happening in what we call the critical learning phase:
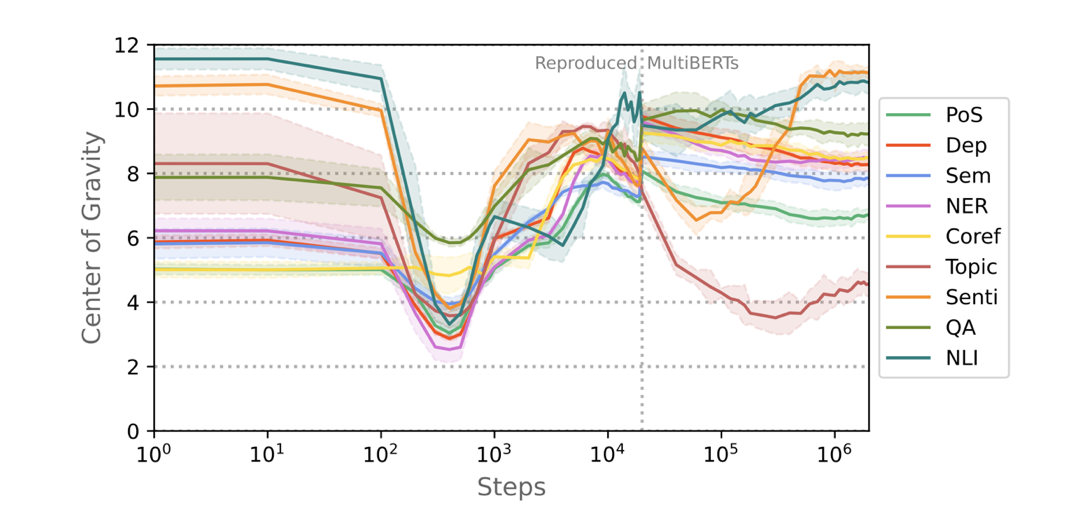
This plot shows at which layer depth in the model, different types of linguistic information are most prevalent. The prior consensus in the NLP community is what you see at the very last stage of training: syntactic tasks are encoded at lower layers than more sematic tasks. However, our experiments show a more complex picture. All tasks first jointly 'climb up' through the model, before splitting up. We interpret this as the model starting in its randomly initialized state, and then becoming useful from the bottom up, before using the remainder of training to specialize. Thanks to our subspace-based approach, we are furthermore able to quantify how similarly different tasks are represented with respect to each other across training:
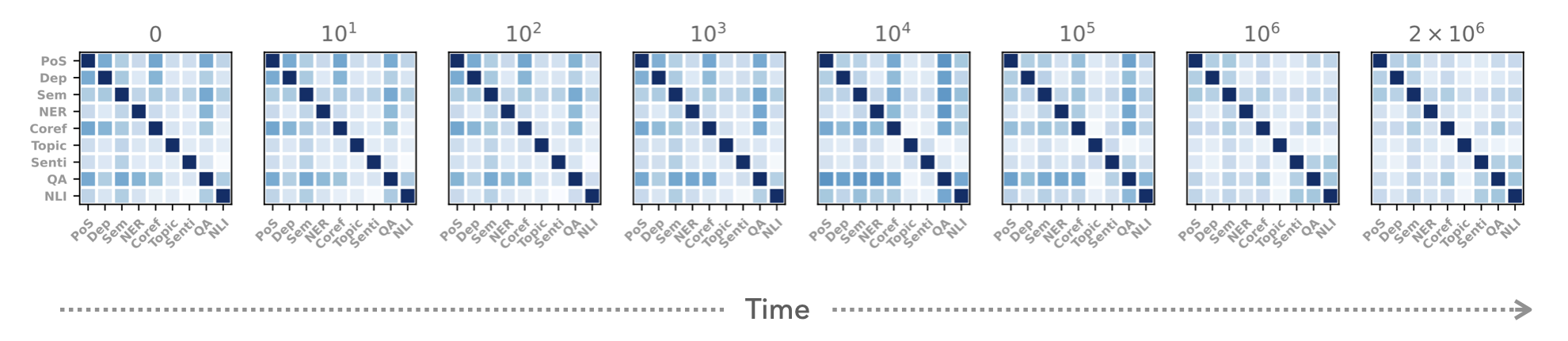
Also here, we see that intuitively similar tasks share a lot of information during the critical learning phase, before diverging later on. Overall, our subspace chronicles show how task variation can be measured using subspace similarity. This helped us better understand how LMs actually learn to become useful. In the future, this could be one avenue towards characterizing more complex tasks (such as the email example), which consists of a mixture of more fundamental linguistic phenomena.
Tasks across Languages
Next, how do we compare tasks across languages? Across languages and models this is actually quite difficult, because models are initialized randomly, meaning that the same information may be represented by wildly different numeric representations. In Spectral Probing, we therefore turn to a different type of subspace: the frequency of task-specific information across the sentence.
Intuitively, linguistic information that changes frequently within the sentence has a high frequency (e.g., syntactic functions of different words), while other information is more constant and has a lower frequency (e.g., the topic of a sentence). Building on seminal work by Alex Tamkin and colleagues, we build a Spectral Probe to extract these frequencies automatically. This produces really nice spectral profiles like these:
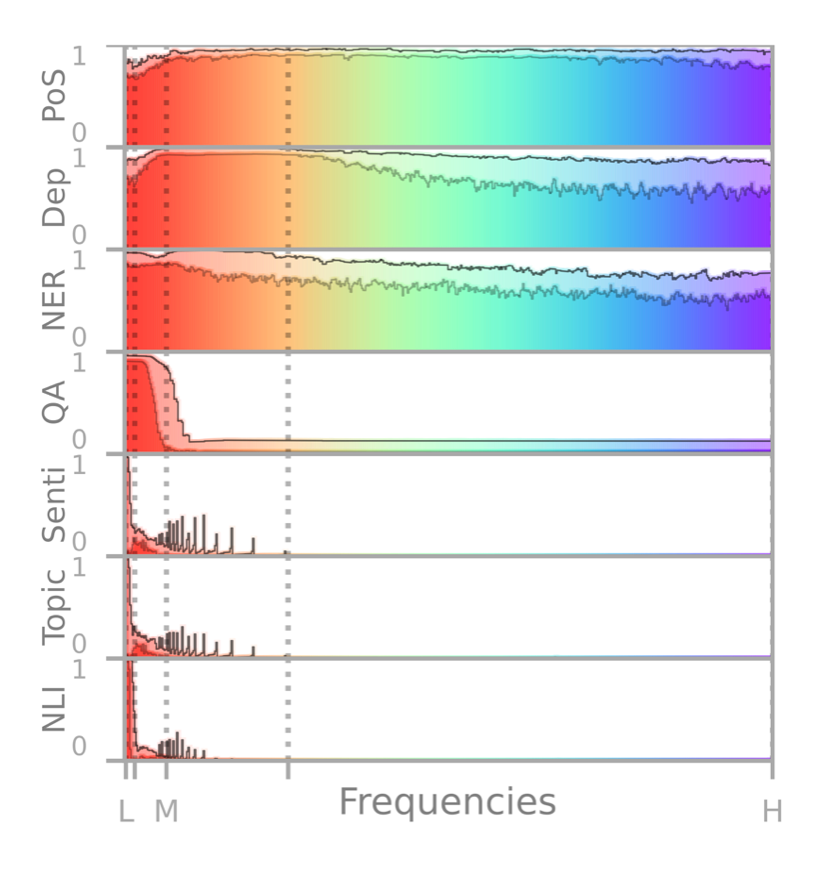
As these rainbows show, word-level part-of-speech tagging covers a lot of higher frequencies, while phrase-level dependency parsing has a lot of mid-frequencies, and sentence-level tasks like topic and sentiment classification only need the lowest frequencies. Not only are these spectrograms pretty to look at, they are also highly consistent across languages!
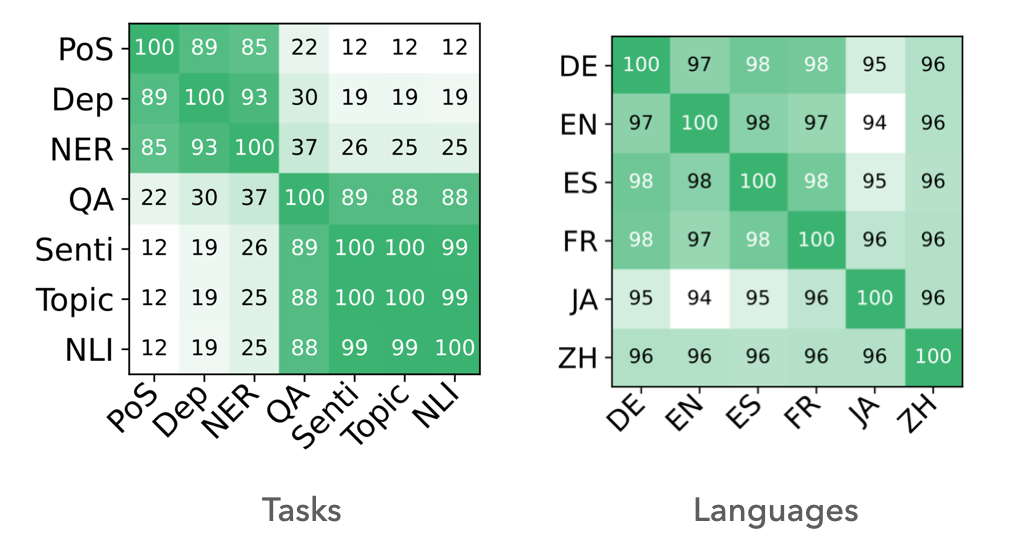
Even for the typologically very distant languages of English and Japanese, we get a 94% overlap across their spectrograms. So, using Spectral Probing, we are able to quantify task similarity consistently—even across languages.
Resources
For when you want to study how linguistic representations change during LM training:
📄 Subspace Chronicles: How Linguistic Information Emerges, Shifts and Interacts during Language Model Training (Müller-Eberstein, van der Goot, Plank and Titov, 2023).
- 🛠️ Subspace Chronicles Implementation (information-theoretic probing with time-travel add-on).
- 📽️ Subspace Chronicles Presentation (ft. Baby BERT!).
For when you want to understand the frequency of your task:
📄 Spectral Probing (Müller-Eberstein, van der Goot and Plank, 2022c).
- 🛠️ Spectral Probing Implementation (extract rainbows from your favorite LMs).
- 📽️ Spectral Probing Presentation (searching for the rainbow at the end of the Copenhagen Metro).
For when you want to philosophize about what a task even is:
- 📄 Establishing Trustworthiness: Rethinking Tasks and Model Evaluation (Litschko*, Müller-Eberstein*, van der Goot, Weber-Genzel and Plank, 2023).
What's Next?
Thanks for joining this recap! Quantifying linguistic variation has been an extremely rewarding project to work on thanks to my wonderful supervisors Barbara, Rob, and Ivan.
A lot has changed in NLP recently, but navigating Variety Space remains as important as ever. For this purpose, I hope this thesis provides some useful tools for computational linguists and ML practitioners alike.
In my own future research, I'll be looking more into how LMs learn to encode all this useful information in the first place, in order to identify universal learning dynamics, which we can leverage to make ML work more efficiently for underserved communities.
I'll also be posting some more behind-the-scenes info on how I structured my PhD, to help out those just getting started. So, until next time!